Elle doit être représentative d’un maximum des cas possibles à rencontrer :
raisons sociales d’administrations ;
comparaison quand une société n’a pas de numéro de téléphone ;
cas des boîtes postales et cedex ;
numéros de téléphone différents dans les services d’une entité…
Pour créer cette base d’exemples des données provenant de plusieurs opérations seront compilées en une seule base qui sera dédoublée avec un compromis entre la méthode 1 et la méthode 3 :
la base sera normalisée pour des comparaisons plus faciles.
les fiches sont triées pour mettre à la suite les doublons probables
Les comparaisons se feront entre 2 fiches qui se suivent ;
des tris seront effectués (ordre de grandeur du nombre de comparaisons 3*N)
mais les comparaisons seront effectuées grâce à des variables prévues pour l’entrée du RN
la sortie sera simplement une moyenne pondérée des comparaisons de ces variables
1 la note de comparaison des raisons sociales
2 la note de comparaison des départements
3 la note de comparaison de la seconde partie du code postal
4 la note de comparaison des téléphones
5 la différence de longueur des champs téléphone
6 la note de comparaison des champs villes
7 la note de comparaison des champs AD1
8 la note de comparaison des champs AD2
9 la note de comparaison des champs AD1.1 AD2.2
10 la note de comparaison des champs AD1.2 AD2.1
11 la présence ou non d’un cedex ou d’une boîte postale dans les champs adresse ou ville
12 le fait que le fichier soit administratif
13 la qualité du fichier
14 les dates de mise à jour
15 la note de comparaison des prénoms
16 la note de comparaison des noms
17 la note de comparaison des fonctions
18 la note de comparaison des services
19 le fait que la longueur d’un champ prénoms soit égale à 0
20 le fait que la longueur d’un champ noms soit égale à 0
21 le fait que la longueur d’un champ fonctions soit égale à 0
22 le fait que la longueur d’un champ services soit égale à 0
La qualité de ces entrées représente en fait beaucoup trop de paramètres. Pourquoi trop ? Parce que pour avoir ces données de manière comparable il faut des fichiers déjà normalisés. Or dans le cas d’une entreprise dans la mesure de ce que j’ai connu, les fichiers sont vraiment différents :
Quelles sont les influences de ces facteurs :
la ligne 5 doit être utilisée pour le calcul de la note attribuée à la comparaison des téléphones
la ligne 14 est souvent inaccessible et de plus invérifiable
les lignes 15 à 22 seront traitées de la manière suivante : les champs civilité prénom nom fonction service seront concaténées puis comparées. Deux notes pourront sortir de ce travail :
la note de comparaison
une note indiquant sur quelle quantité d’information porte cette note
les adresses sont souvent écrites dans le bon ordre on pourra donc les concaténer pour ne faire qu’une seule comparaison
Suite aux nombreux travaux réalisés une base de données de plus de 150 000 adresses a été constituée. Celle-ci représente dans l’absolu entre onze milliards deux cent cinquante millions sept cent cinquante mille et onze milliards deux cent quarante-neuf millions deux cent cinquante mille combinaisons.
1 la note de comparaison des raisons sociales
3+6 la note de comparaison des champs villes si les cp sont # et il y a 1 cedex, BP
4 la note de comparaison des téléphones
7 la note de comparaison des champs AD1
12 le fait que le fichier soit administratif
13 la qualité du fichier
15 la note de comparaison des personnes : civilité prénoms noms fonctions services
disparaissent :
2 la note de comparaison des départements: on ne compare que à l’intérieur d’un département
3 la note de comparaison de la seconde partie du code postal
6 la note de comparaison des champs villes
5 la différence de longueur des champs téléphone : la note de comparaison su téléphone en tient compte
8 la note de comparaison des champs AD2
9 la note de comparaison des champs AD1.1 AD2.2
10 la note de comparaison des champs AD1.2 AD2.1
une seule ligne d’adresse
11 la présence ou non d’un cedex ou d’une boîte postale dans les champs adresse ou ville inutile la seule précaution à prendre est de supprimer cette présence dans le champ concerné.
13 la qualité du fichier il faudra rendre ce paramètre plus objectif
14 les dates de mise à jour : impossible à déterminer en général
15 la note de comparaison des prénoms
16 la note de comparaison des noms
17 la note de comparaison des fonctions
18 la note de comparaison des services
19 le fait que la longueur d’un champ prénoms soit égale à 0
20 le fait que la longueur d’un champ noms soit égale à 0
21 le fait que la longueur d’un champ fonctions soit égale à 0
22 le fait que la longueur d’un champ services soit égale à 0
il reste donc 10 entrées
pour la version définitive on retient en fait :
1 la note de comparaison d’un champ contenant civilité prénom nom fonction
2 la note de comparaison des raisons sociales
3 la comparaison des adresses concaténées et standardisées
4 la note de comparaison du critère composé
5 la note de comparaison des villes
6 la qualité du fichier
7 la fiche administration / entreprise
8 la note de comparaison présence BP Cedex
9 la note de comparaison des numéros de téléphone
dans la version prévue où tous les enregistrements du fichier source sont comparés entre eux et par rapport au repoussoir sur plusieurs variables :
20*(N*N+N*N1) comparaisons.
on a 100 depts
100*10*(1 500*1500)/2= 1 125 000 000
450 000 000
la comparaison de deux phrases / mots pour donner une note entre 0 et 1 s’effectue aux - nombreuses - variations près suivant le principe suivant :
soient les deux mots à comparer « turbin » et « turban »
| t | u | r | b | i | n | |
| t | u | r | b | a | n | |
| égalité | 1 | 1 | 1 | 1 | 0 | 1 |
| coefs | 6 | 5 | 4 | 3 | 2 | 1 |
| notes | 6 | 5 | 4 | 3 | 0 | 1 |
| total | 19 |
total coefficients 21 (n lettres : n*(n+1)/2)
coefs 6 5 4 3 2 1 total coefficients 21 (6 lettres à n*(n+1)/2)
note comparaison 19/21=0.9 on obtient donc une note entre 0 et 1
Nous allons appeler l’entrée 4 (la note de comparaison du critère composé) K4.
5000 fiches ont été triées dans Excel suivant ce critère. On a calculé, toujours dans Excel le calcul de la note entre une fiche et celle qui suivait. Puis pour chacun de ces couples on a effectué une comparaison manuelle pour chercher les doublons.
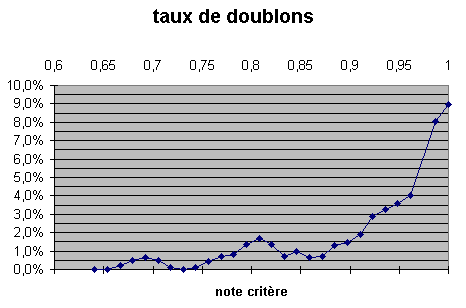
comme il y a moins de couples où la note est 1 le résultat de ce travail peut se résumer dans le graphique suivant :
l'axe x représente la note obtenue pour K4
en rouge ce sont les doublons et en gris les non doublons
La droite représente l’hyperplan recherché pour notre classifieur.
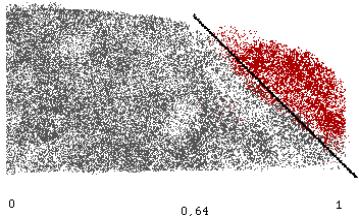
On retient donc de cette première approche que K4 si il ne permet pas de faire le distinguo doublon non doublon il va faire le distinguo entre doublon impossible et doublon possible. On va donc retenir pour notre base d'exemple que les couples où K4 >0,64.
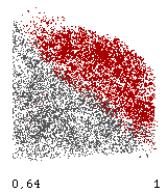
Ce qui permet de ramener le problème au cas suivant :
C’est sur la base des doublons possibles que l’on trouvera la base d’apprentissage
Cette base doit être créée manuellement en effectuant les comparaisons de 20 000 couples de données.
Cette comparaison s’effectue dans le tableur de la manière suivante :
Une feuille contient toutes les adresses connues triées dans l’ordre du critère. Un champ contient les valeurs de la comparaison de deux fiches consécutives suivant K4. Tous les couples ayant une note supérieure à 0.64 sont présentés à l’écran.
Deux boutons sont présents à l’écran : doublon et différent. Une macro copie les résultats dans une autre feuille sous la forme suivante :
Numéro de la comparaison,
Numéro de la première fiche,
Numéro de la seconde fiche,
0 si les deux fiches sont différentes, 1 si c’est un doublon.
Les deux premières étapes ont permis d’éviter bon nombre de comparaisons inutiles mais le travail manuel fut quand même important.
J’ai calculé les valeurs de K4 en utilisant Excel car c’est un critère d’une longueur définie et même si c’est un calcul important ce n’est qu’un calcul : cela ne nécessite pas de préparation.
![]() Pour les autres critères il a fallu utiliser un outil plus puissant et créer des procédures de préparation et de calcul.
Pour les autres critères il a fallu utiliser un outil plus puissant et créer des procédures de préparation et de calcul.
L’outil choisi est quatrième dimension (4D) outil de gestion de base de données doté d’un langage très complet et en français.
6 fichiers sont nécessaires
20 procédures sont nécessaires 19 pour préparer les fiches et calculer les notes et une au moins sera créée pour calculer la sortie quand les paramètres du réseau seront calculés. On effectue entre autres les opérations suivantes :
Puis pour tous les couples comparés à la main on fait les comparaisons automatiques de chaque champ.
Sauf pour :
Tous ces calculs permettent de créer la base d’exemples pour l’apprentissage du réseau.
Le faible nombre de doublons (413) trouvés sur les 20 000 comparaisons fait qu’une base d’apprentissage reflétant cette proportion n’arriverait jamais à faire apprendre quoi que ce soit au réseau. De plus j’ai préféré laisser tous les doublons dans la base d’apprentissage.
Celle ci est donc composée à environ un tiers de doublons et deux tiers de non doublons choisis au hasard. Ceci donne 1265 enregistrements triés au hasard.
La base de validation contient les doublons mais contient au total 4778 fiches ce qui correspond à 8.6% de doublons ce qui est une réalité possible. Les doublons sont placés de manière aléatoire dans la liste.
On va la récupérer sous la forme d’un fichier texte et calculer les différents paramètres (poids et constantes des neurones) dans Excel.
|
|
|
|